CNN卷积神经网络图像物体对象分类
这部分重点介绍卷积神经网络,也称为CNN或Convnet。CNN是一种特殊类型的神经网络,特别适合图像数据。自2012年以来,ImageNet竞赛长期以CNN架构获胜。
1. 前馈网络的局限性
参数爆炸
前馈神经网络是每一层都是全连接,需要展平图像才能将其用作全连接层的输入。我们看到在m个神经元之后有n个神经元的全连接层具有$(m+1)*n$个参数。
如果我们的网络有10个神经元的单层,并且如果我们使用分辨率为64x64x3的图像,则该层将有122880个权重和10个偏置。随着更多层、更多神经元和更高图像分辨率,将造成参数爆炸。值得庆幸的是,卷积层将有助于解决这个问题!
我们现在将图像视为输入体积,而不是展平图像。与全连接层相反,卷积层将是局部连接的。实际上,卷积层中的每个神经元只会连接到输入量的一小部分。
2. 卷积层(conv layer)
卷积层由过滤器组成。这样的过滤器是HxWxD的可学习权重数组,它们在输入量上滑动或卷积。每个过滤器都在整个输入体积上进行卷积。这种过滤器的卷积创建了一个称为特征图的 2D 输出数组。因为一个卷积层有多个过滤器,它输出多个特征图。它们将堆叠在一起以创建输出体积。
卷积层中的过滤器由两个超参数定义:高度和宽度。它们通常很小,最常见的过滤器尺寸是3x3或5x5。
卷积运算
除了过滤器大小F之外,卷积层还有额外的超参数。步幅S控制过滤器移动步长的大小。填充P通过向输入的边界添加零(或其他值)来控制输出的大小。
可以使用以下公式计算输出体积的空间维度。以下公式计算输出体积的宽度,用相同的公式计算高度。
\[W_o = \frac{W - F + 2}{S} + 1\]过滤器充当卷积层中的特征检测器,层越深,过滤器越能检测细微的特征。例如,在训练狗猫图像分类的算法时,深层过滤器可能是左耳检测器。
卷积层中的参数数量由过滤器尺寸、过滤器数量和输入体积D的深度决定。如果我们考虑具有32个3x3过滤器的尺寸:
-
每个过滤器有 3x3xD + 1 个参数
-
整个层有 (3x3xD+1)x32 个参数
CNN通常有几百万个参数,但一些面向移动应用的架构几乎没有达到一百万。
3. 池化层
Python实现池化层(以下为最大池化层实现)
池化层在CNN中非常常见。它们通过聚合空间信息来减少网络中的参数数量,通常是取平均值(平均池化)或最大值(最大池化)。它们没有任何可学习的参数。
import argparse
import numpy as np
from utils import check_output
def get_paddings(array, pool_size, pool_stride):
"""
get padding sizes
args:
- array [array]: input np array NxwxHxC
- pool_size [int]: window size
- pool_stride [int]: stride
returns:
- paddings [list[list]]: paddings in np.pad format
"""
_, w, h, _ = array.shape
wpad = (w // pool_stride) * pool_stride + pool_size - w
hpad = (h // pool_stride) * pool_stride + pool_size - h
return [[0, 0], [0, wpad], [0, hpad], [0, 0]]
def get_output_size(shape, pool_size, pool_stride):
"""
given input shape, pooling window and stride, output shape
args:
- shape [list]: input shape
- pool_size [int]: window size
- pool_stride [int]: stride
returns
- output_shape [list]: output array shape
"""
w = shape[1]
h = shape[2]
new_w = (w - pool_size) / pool_stride + 1
new_h = (h - pool_size) / pool_stride + 1
return [shape[0], int(new_w), int(new_h), shape[3]]
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Download and process tf files')
parser.add_argument('-f', '--pool_size', required=True, type=int, default=3,
help='pool filter size')
parser.add_argument('-s', '--stride', required=True, type=int, default=3,
help='stride size')
args = parser.parse_args()
input_array = np.random.rand(1, 224, 224, 16)
pool_size = args.pool_size
pool_stride = args.stride
# padd the input layer
paddings = get_paddings(input_array, pool_size, pool_stride)
padded = np.pad(input_array, paddings, mode='constant', constant_values=0)
# get output size
output_size = get_output_size(padded.shape, pool_size, pool_stride)
output = np.zeros(output_size)
idx = 0
for i in range(0, input_array.shape[1], pool_stride):
jdx = 0
for j in range(0, input_array.shape[2], pool_stride):
local = padded[:, i: i + pool_stride, j: j + pool_stride, :]
local_max = np.max(local, axis=(1, 2))
output[:, idx, jdx, :] = local_max
jdx += 1
idx += 1
check_output(output)
4. 典型的卷积网络架构
CNN架构中很常见的一种架构就是不断重复以下三层网络以达到深层神经网络的架构。
-
卷积层
-
激活层
-
池化层
另一种常见的策略则是随着网络深度的增加而增加卷积层中的过滤器数量。
CNN架构最后一个卷积层的输出被展平并馈送到一个经典的前馈神经网络,称为分类器。由于分类器的第一个全连接层需要固定大小的输入,因此具有这种设计的CNN需要固定分辨率的输入图像。
Dropout
Dropout在2014年的一篇论文中被引入,以防止过度拟合。Dropout可用于全连接层或卷积层,并在训练期间简单地随机禁用神经元。Dropout没有任何可学习的参数,只有一个超参数,即神经元被禁用的概率p。
需要注意的是,Dropout在训练和测试期间的行为并不相似。事实上,因为我们希望模型在生产中的行为是确定性的,所以在测试推理阶段dropout被关闭并且神经元不再随机禁用。这样做的主要后果是需要缩放神经元输出。为了理解这一点,让我们考虑一个包含10个神经元的简单全连接层。使用 0.5 的Dropout概率。在训练过程中,下一个全连接层中的神经元平均将接收来自5个神经元的输入。但是在测试期间,相同的神经元将接收来自10个神经元的输入。为了在训练和测试期间获得类似的行为,我们需要在测试期间将神经元的输出缩放 0.5。
在实践中,可以使用一种称为倒置 dropout 的方法,在训练期间进行缩放。因为我们希望模型在部署时尽可能快,所以宁愿在训练期间而不是在推理时进行这种缩放操作。
批量标准化
Batch Normalization 或 Batchnorm 在 2015 年的一篇论文中首次引入。批量标准化通过计算批处理统计数据并使用这些统计数据缩放其输入。Batchnorm 可以改善神经网络的收敛时间。 与 Dropout 类似,Batchnorm 在训练和测试过程中表现不同。在训练期间,该层计算批次统计数据的指数移动平均值。在测试期间,使用这些统计信息而不是来自测试批次的批次统计信息。
几种经典卷积神经网络架构
Alexnet
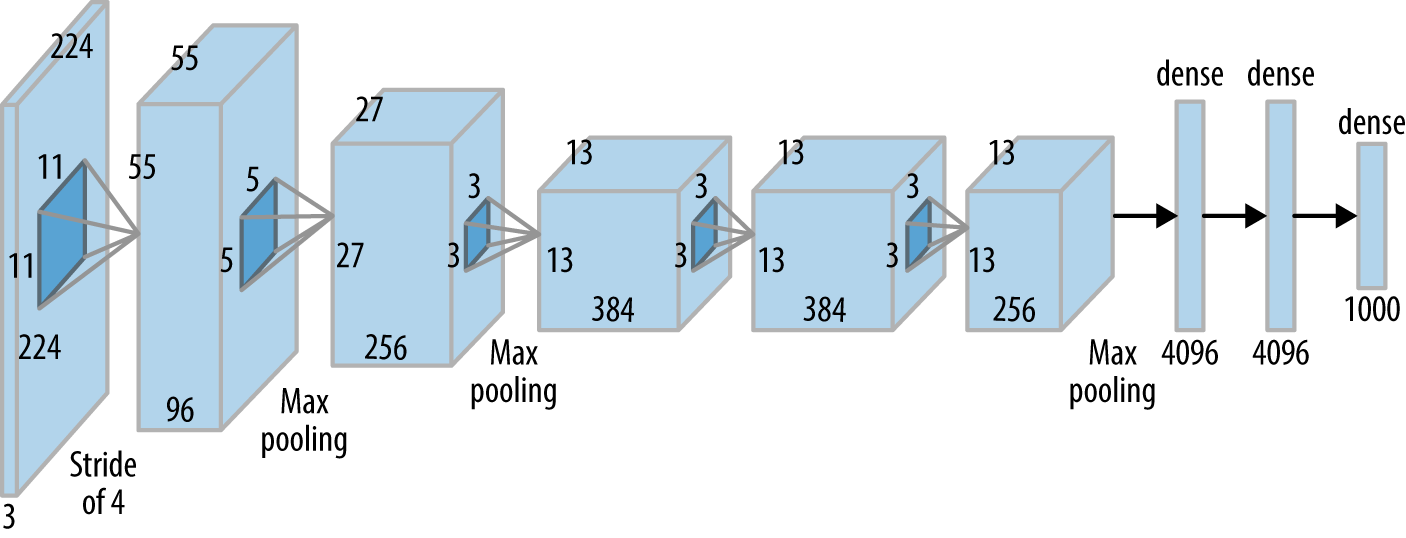
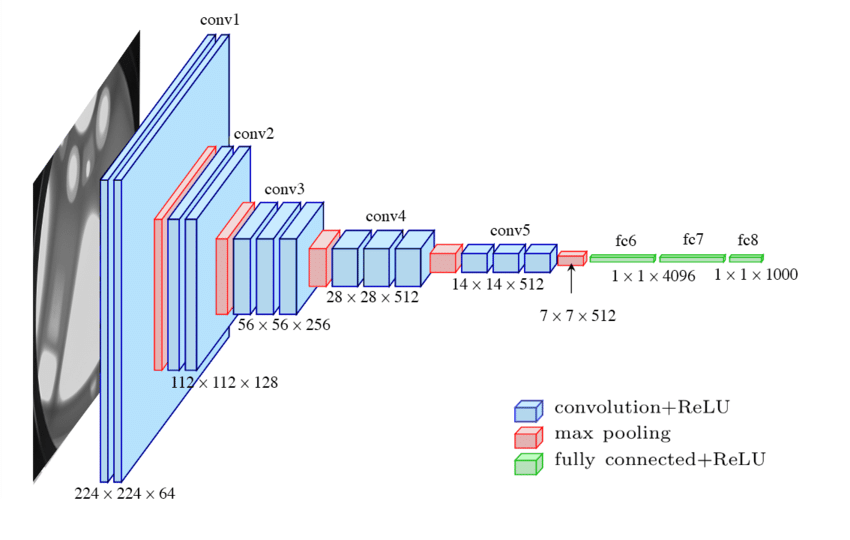
VGG
VGG架构核心概念:
- 使用较小的过滤器尺寸,如 3x3 过滤器。
- 使用卷积块:2 或 3 个卷积层块后跟一个池化层。
通过用小过滤器堆叠多个卷积层,我们创建了一个块,该块的参数比具有更大过滤器尺寸的单个层少,同时具有相同的有效感受野和更多的非线性。
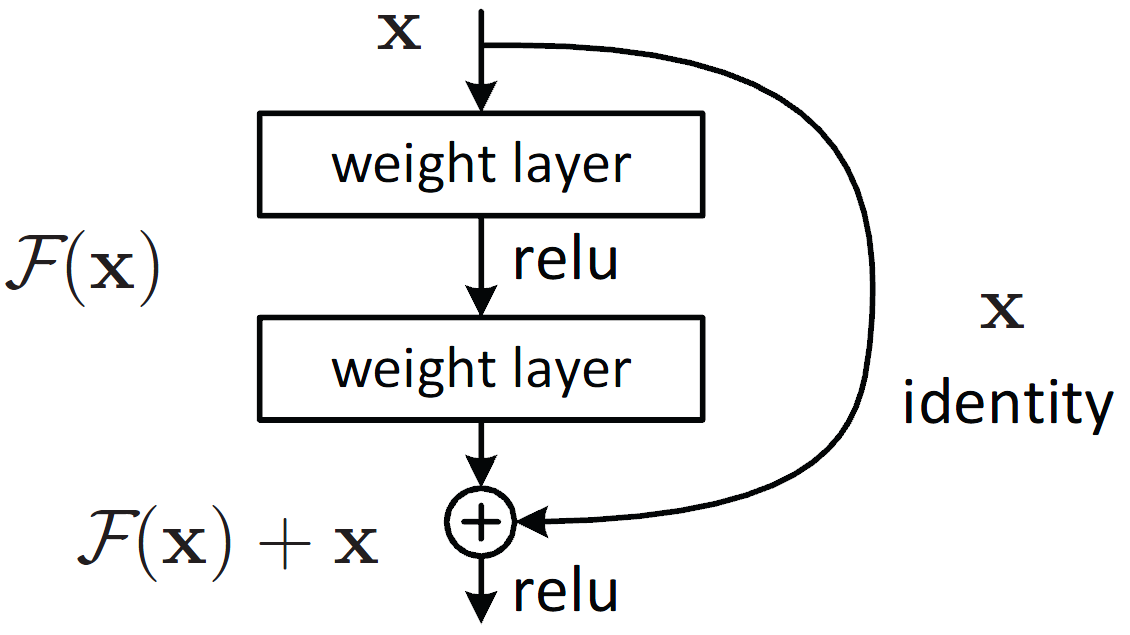
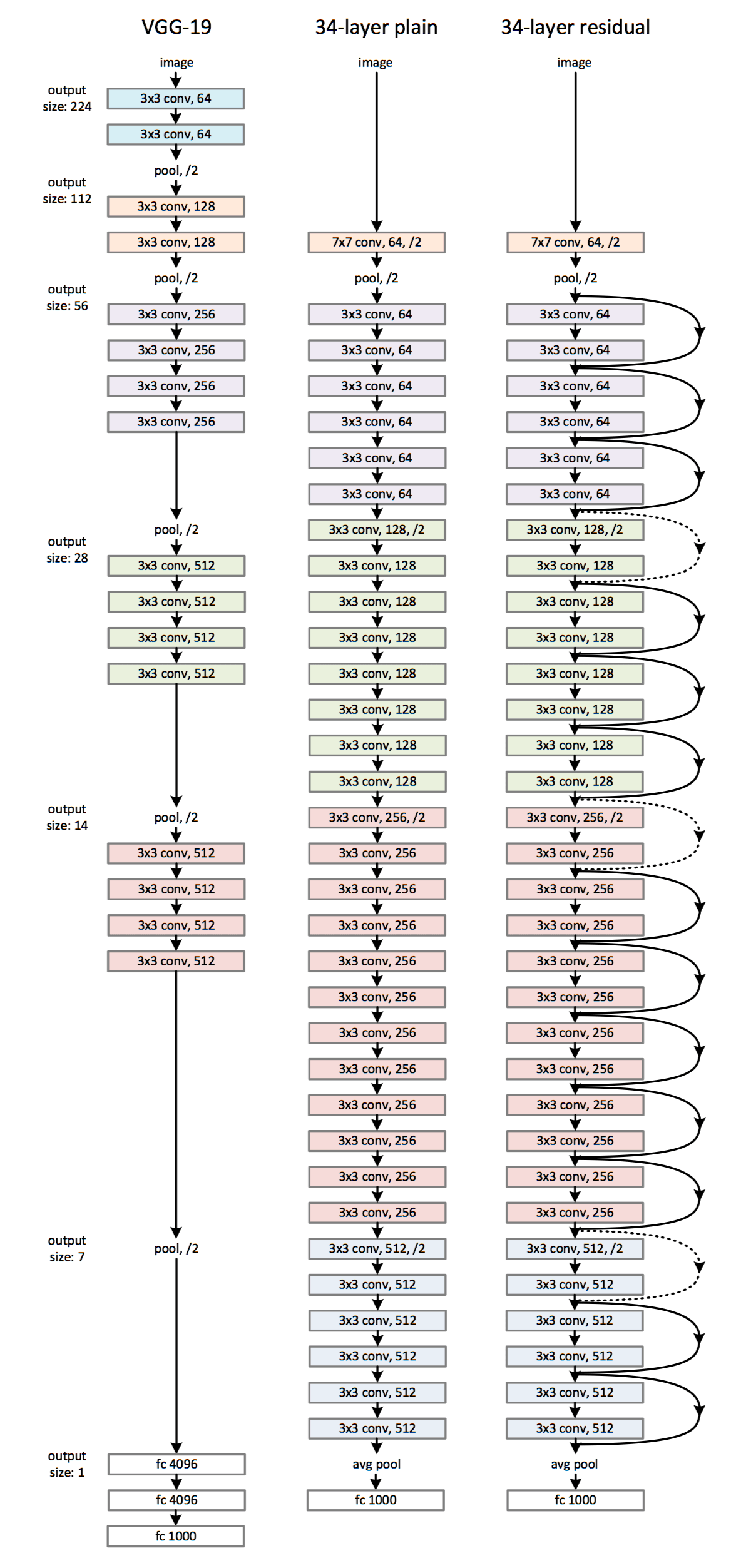
ResNet
在 2015 年发表的另一篇非常重要的论文中,作者介绍了 Resnet 架构。他们意识到具有更多层的网络开始表现不佳。为了解决这个问题并允许更深的网络,作者引入了残差连接或跳过连接的概念。 跳过连接只是将一层或一组层的输入添加到其输出中。通过这样做,它将缓解与激活函数相关的梯度传播问题。
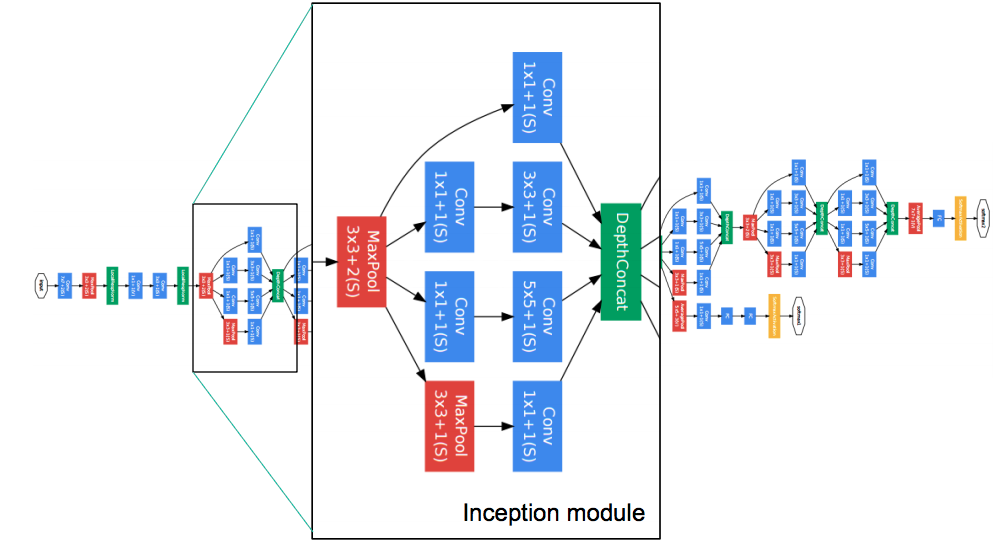
GoogLeNet
GoogLeNet 的突破主要在于在“层”内使用多个不同尺寸的卷积过滤器,也就是使用了Inception模块。
TensorFlow实现简单卷积神经网络
import argparse
import logging
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPooling2D
from utils import get_datasets, get_module_logger, display_metrics
def create_network():
net = tf.keras.models.Sequential()
input_shape = [32, 32, 3]
net.add(Conv2D(6, kernel_size=(3, 3), strides=(1, 1), activation='relu',
input_shape=input_shape))
net.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
net.add(Conv2D(16, kernel_size=(3, 3), strides=(1, 1), activation='relu'))
net.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
net.add(Flatten())
net.add(Dense(120, activation='relu'))
net.add(Dense(84, activation='relu'))
net.add(Dense(43))
return net
if __name__ == '__main__':
logger = get_module_logger(__name__)
parser = argparse.ArgumentParser(description='Download and process tf files')
parser.add_argument('-d', '--imdir', required=True, type=str,
help='data directory')
parser.add_argument('-e', '--epochs', default=10, type=int,
help='Number of epochs')
args = parser.parse_args()
logger.info(f'Training for {args.epochs} epochs using {args.imdir} data')
# get the datasets
train_dataset, val_dataset = get_datasets(args.imdir)
model = create_network()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(x=train_dataset,
epochs=args.epochs,
validation_data=val_dataset)
display_metrics(history)
5. 迁移学习
使用迁移学习的四种主要情况
迁移学习涉及采用预先训练的神经网络并使神经网络适应新的不同数据集。迁移学习主要考虑两个场景的数据情况:
- 新数据集的大小
- 新数据集与原始数据集的相似度
业务场景不同,使用迁移学习的方法会有所不同。主要有四种情况:
-
- 新数据集小,新数据与原始训练数据相似
-
- 新数据集小,新数据与原始训练数据不同
-
- 新数据集大,新数据与原始训练数据相似
-
- 新数据集大,新数据与原始训练数据不同
![]()
一个大型数据集可能有 100 万张图片。 一个小数据集可能有两千张图像。大数据集和小数据集之间的分界线有些主观。在对小数据集使用迁移学习时,过度拟合是一个问题。
狗的图像和狼的图像将被认为是相似的; 这些图像将具有共同的特征。花卉图像数据集与狗图像数据集不同。
四个迁移学习案例中的每一个都有自己的方法。在下面的部分中,我们将一一查看每个案例。
示范网络
为了解释每种情况是如何工作的,我们将从一个通用的预训练卷积神经网络开始,并解释如何针对每种情况调整网络。示例网络包含三个卷积层和三个全连接层:
![]()
以下是卷积神经网络功能的概述:
-
第一层将检测图像中的边缘
-
第二层将检测形状
-
第三层将检测更高级别的特征
每个迁移学习案例都会以不同的方式使用预训练的卷积神经网络。
案例 1:小数据集,相似数据
![]()
如果新数据集很小并且与原始训练数据相似:
-
切掉神经网络的末端
-
添加一个新的全连接层,与新数据集中的类数相匹配
-
随机化新的全连接层的权重
-
冻结来自预训练网络的所有权重
-
训练网络更新新的全连接层的权重
-
为了避免在小数据集上过度拟合,原始网络的权重将保持不变,而不是重新训练权重。
-
由于数据集相似,来自每个数据集的图像将具有相似的更高级别的特征。因此,大部分或所有预训练的神经网络层已经包含有关新数据集的相关信息,应该保留。
![]()
案例 2:小数据集,不同的数据
![]()
如果新数据集很小并且与原始训练数据不同:
-
在网络开头附近切掉大部分预训练层
-
向剩余的预训练层添加一个新的全连接层,该层与新数据集中的类数相匹配
-
随机化新的全连接层的权重; 冻结来自预训练网络的所有权重
-
训练网络更新新的全连接层的权重
-
由于数据集较小,过拟合仍然是一个问题。 为了防止过拟合,原始神经网络的权重将保持不变,就像第一种情况一样。
-
但是原始训练集和新数据集不共享更高级别的特征。在这种情况下,新网络将只使用包含较低级别特征的层。
![]()
案例 3:大数据集,相似数据
![]()
如果新数据集很大并且与原始训练数据相似:
-
删除最后一个全连接层并替换为与新数据集中的类数匹配的层
-
随机初始化新全连接层的权重
-
使用预训练的权重初始化其余的权重
-
重新训练整个神经网络
-
在大型数据集上进行训练时,过度拟合不是一个问题; 因此,您可以重新训练所有权重。
-
由于原始训练集和新数据集共享更高级别的特征,因此也使用了整个神经网络。
![]()
案例 4:大数据集,不同数据
![]()
如果新数据集很大并且与原始训练数据不同:
-
删除最后一个全连接层并替换为与新数据集中的类数匹配的层
-
使用随机初始化的权重从头开始重新训练网络
-
或者可以使用与“大型和类似”数据案例相同的策略
-
即使数据集与训练数据不同,从预训练网络初始化权重可能会使训练更快。所以这种情况与具有大型相似数据集的情况完全相同。
-
如果使用预训练网络作为起点不能产生成功的模型,另一种选择是随机初始化卷积神经网络权重并从头开始训练网络。
![]()
6. 数据增广
数据增广是一种无需捕获更多图像即可增加训练数据集可变性的方法。通过在训练期间应用像素级和几何变换,我们可以人为地模拟不同的环境。例如,可以使用模糊过滤器来模拟运动模糊。应该仔细选择数据增广策略。
在 Tensorflow 中可以使用 Keras API 来创建组合进行数据增广。
Albumentations
许多图像增广库可用,但最受欢迎的库之一是Albumentations。它提供了快速简便的方法来将像素级和几何变换应用于图像和标签,包括边界框。
使用Albumentations实现数据增广
import argparse
from functools import partial
import albumentations as A
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing import image_dataset_from_directory
from utils import plot_batch
transforms = A.Compose([A.Rotate(limit=30, p=0.5),
A.Blur(blur_limit=5, p=0.5)])
def aug_fn(image):
""" augment an image """
aug_data = transforms(image=image.squeeze())
aug_img = aug_data["image"]
aug_img = tf.cast(aug_img/255.0, tf.float32)
return aug_img
def process_data(image, label):
""" wrapper function to apply augmentation """
aug_img = tf.numpy_function(func=aug_fn, inp=[image], Tout=tf.float32)
return aug_img, label
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Augment dataset')
parser.add_argument('-d', '--imdir', required=True, type=str,
help='data directory')
args = parser.parse_args()
dataset = image_dataset_from_directory(args.imdir,
image_size=(32, 32),
validation_split=0.1,
subset='training',
seed=123,
batch_size=1)
dataset = dataset.map(process_data).batch(256)
for X,Y in dataset:
batch_np = X.numpy()
plot_batch(batch_np)
break