机器学习工作流
1. 介绍
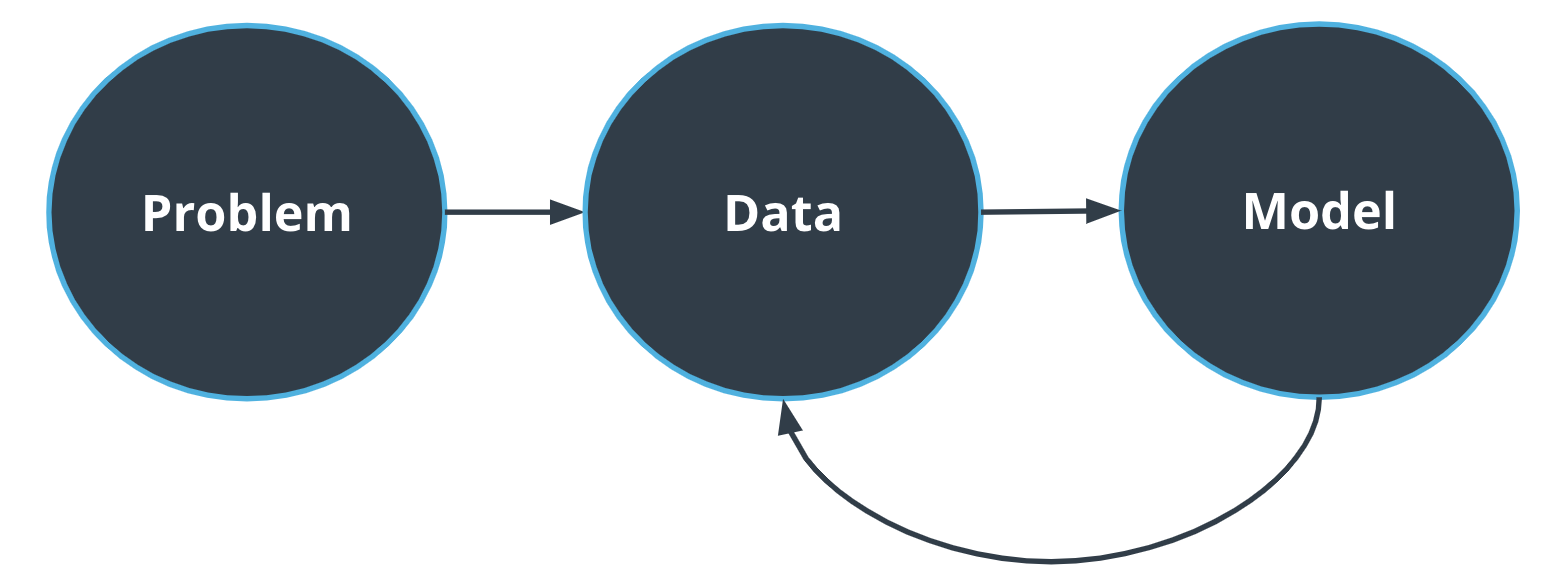
机器学习基本流程是定义要解决的问题,收集训练数据来训练出合适的模型,最后把训练出的模型应用于数据以解决问题。
- 设置问题边界
- 收集训练数据
- 训练模型
2. 设置问题边界
2.1 是否需要机器学习
是否使用机器学习至少要考虑几个方面问题,如性能、推理时间、数据成本等。
除非参加机器学习竞赛,否则模型的性能很少是唯一关心的事情。例如,在自动驾驶汽车系统中,模型的推理时间(提供预测所需的时间)也是一个重要因素。每秒可以消化5张图像的模型比每秒只能处理1张图像的模型要好,即使第二张图像表现更好。在这种情况下,推理时间也是选择模型的一个重要指标。
了解数据管道非常重要,它将推动模型开发。在某些情况下,获取新数据相对容易,但注释它们(例如通过关联类名)可能很昂贵。在这种情况下,可能需要创建一个只要较少数据或可以处理未标记数据的模型。
2.2 确定主要利益相关者
作为机器学习工程师,很少会成为产品的最终用户。因此,需要确定要解决问题的不同利益相关者。为什么?因为这将推动模型开发。
自动驾驶汽车技术将对我们的生活产生巨大影响。这项技术至少涉及以下不同的利益相关者:如日常使用消费者、保险公司、城市规划、法律法规制定者、环境等。
2.3 选择指标
每个机器学习问题都需要自己的指标,而像 Accuracy 这样的一些指标可能适用于许多问题,但需要牢记错误预测的后果。让我们考虑以下问题:您正在构建垃圾邮件分类算法,您应该瞄准极少的假阳性(误报),因为我们不希望算法将一些可能有用的电子邮件分类到垃圾邮件文件夹。对于假阴性(没有检测出来)可以有较高的容忍度,位于收件箱中的垃圾邮件,可以由用户手动删除。
分类和对象检测指标
\[Precision = \frac{TP}{TP + FP}\]精度:在归类为特定类别的元素中,我们做对了多少?例如,我们将6张图像归类为包含汉堡,而其中只有5张实际上包含一个汉堡,则精度为5/6。
\[Recall = \frac{TP}{TP + FN}\]召回:正确分类的图像数量除以图像总数。例如,我们有40张汉堡图片,我们正确分类了其中的15张,则召回率为15/40。
我们对目标检测使用相同的精度和召回率定义,但我们考虑每个图像的目标实例数。
\[Accuracy = \frac{TP + TN}{TP + FN + FP + TN}\]准确率:(对于图像分类问题)正确分类的图像数量占图像总数。
Python实现分类和对象检测指标
先实现检测框iou计算函数(iou.py),再对iou计算精度和召回率(precision_recall.py)
import numpy as np
from utils import get_data, check_results
def calculate_iou(gt_bbox, pred_bbox):
"""
calculate iou
args:
- gt_bbox [array]: 1x4 single gt bbox
- pred_bbox [array]: 1x4 single pred bbox
returns:
- iou [float]: iou between 2 bboxes
"""
xmin = np.max([gt_bbox[0], pred_bbox[0]])
ymin = np.max([gt_bbox[1], pred_bbox[1]])
xmax = np.min([gt_bbox[2], pred_bbox[2]])
ymax = np.min([gt_bbox[3], pred_bbox[3]])
intersection = max(0, xmax - xmin) * max(0, ymax - ymin)
gt_area = (gt_bbox[2] - gt_bbox[0]) * (gt_bbox[3] - gt_bbox[1])
pred_area = (pred_bbox[2] - pred_bbox[0]) * (pred_bbox[3] - pred_bbox[1])
union = gt_area + pred_area - intersection
return intersection / union
def calculate_ious(gt_bboxes, pred_bboxes):
"""
calculate ious between 2 sets of bboxes
args:
- gt_bboxes [array]: Nx4 ground truth array
- pred_bboxes [array]: Mx4 pred array
returns:
- iou [array]: NxM array of ious
"""
ious = np.zeros((gt_bboxes.shape[0], pred_bboxes.shape[0]))
for i, gt_bbox in enumerate(gt_bboxes):
for j, pred_bbox in enumerate(pred_bboxes):
ious[i,j] = calculate_iou(gt_bbox, pred_bbox)
return ious
import numpy as np
from iou import calculate_ious
from utils import get_data
def precision_recall(ious, gt_classes, pred_classes):
"""
calculate precision and recall
args:
- ious [array]: NxM array of ious
- gt_classes [array]: 1xN array of ground truth classes
- pred_classes [array]: 1xM array of pred classes
returns:
- precision [float]
- recall [float]
"""
xs, ys = np.where(ious>0.5)
# calculate true positive and true negative
tps = 0
fps = 0
for x, y in zip(xs, ys):
if gt_classes[x] == pred_classes[y]:
tps += 1
else:
fps += 1
matched_gt = len(np.unique(xs))
fns = len(gt_classes) - matched_gt
precision = tps / (tps+fps)
recall = tps / (fps + fns)
return precision, recall
3. 收集训练数据
3.1 数据收集与可视化
在许多情况下,我们需要收集自己的数据。但我们通常能利用开源数据集来训练算法模型,例如 Google Open Image Dataset。但是,请记住最终目标以及将部署或使用算法的领域。 由于所谓的领域区别,在特定数据集上训练的算法可能在另一个数据集上表现不佳。例如,根据使用特定相机收集的数据训练的行人检测算法可能无法准确检测使用其他相机拍摄的图像上的行人。
图像数据在机器学习工作流程中经历的步骤是:传感器捕捉数据 -> 预处理算法清洗数据 -> 标注数据 -> 数据进入机器学习算法训练。
数据对于机器学习工程师非常重要,ML工程师不只是训练很酷的算法,还包括创建数据处理管道,机器学习算法的性能依赖于数据的质量。
Python实现数据可视化
import glob
import json
import os
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
from PIL import Image
from utils import get_data
def viz(ground_truth):
"""
create a grid visualization of images with color coded bboxes
args:
- ground_truth [list[dict]]: ground truth data
"""
paths = glob.glob('../../data/images/*')
# mapping to access data faster
gtdic = {}
for gt in ground_truth:
gtdic[gt['filename']] = gt
# color mapping of classes
colormap = {1: [1, 0, 0], 2: [0, 1, 0], 4: [0, 0, 1]}
f, ax = plt.subplots(4, 5, figsize=(20, 10))
for i in range(20):
x = i % 4
y = i % 5
filename = os.path.basename(paths[i])
img = Image.open(paths[i])
ax[x, y].imshow(img)
bboxes = gtdic[filename]['boxes']
classes = gtdic[filename]['classes']
for cl, bb in zip(classes, bboxes):
y1, x1, y2, x2 = bb
rec = Rectangle((x1, y1), x2- x1, y2-y1, facecolor='none',
edgecolor=colormap[cl])
ax[x, y].add_patch(rec)
ax[x ,y].axis('off')
plt.tight_layout()
plt.show()
if __name__ == "__main__":
ground_truth, _ = get_data()
viz(ground_truth)
3.2 探索性数据分析
机器学习算法对领域转移非常敏感。 这种领域转移可能发生在不同的层面:
- 天气/光照条件:例如,仅在晴天图像上训练的算法在显示雨天或夜间数据时表现不好。
- 传感器:传感器的变化或不同的处理方法将产生领域转移。
- 环境:例如,在低强度交通数据上训练的算法在高强度交通数据上表现不佳。
广泛的探索性数据分析(EDA)对于任何ML项目的成功都至关重要。在这个阶段,机器学习工程师要熟悉数据集并发现数据的任何潜在挑战。EDA是机器学习项目的重要组成部分,甚至可能需要花费几天时间来做探索性数据分析。对于视觉问题,也许需要至少查看数据集中的1,000幅图像!

如上图是德国交通标志数据集的一部分,可以看到一些图片比其他的要暗,一些图片比其他图片更模糊,在这里遮挡不是问题。
3.3 交叉验证
ML算法的目标是部署在生产环境中。例如,创建对象检测算法可以直接部署在自动驾驶汽车中。但在部署此类算法之前,需要确保它在遇到的任何环境中都能表现良好。换句话说,需要评估模型的泛化能力。这里涉及到3个重要概念:
- 过拟合:模型不能很好地泛化
- 偏差-方差权衡:创建平衡模型
- 交叉验证:一种评估模型泛化能力的技术
过拟合
当模型过度拟合时,它就失去了泛化能力。当所选模型过于复杂并开始提取噪声而不是有意义的特征时,通常会发生这种情况。例如,当汽车检测模型开始提取数据集中汽车的品牌特定特征(例如汽车标志)而不是更广泛的特征(车轮、形状等)时,它就会过拟合。
过拟合提出了一个非常重要的问题。如何知道模型是否可以正确泛化?事实上,当单个数据集可用时,要知道我们是否创建了一个过度拟合或只是表现良好的模型非常具有挑战性。
偏差和方差权衡
偏差-方差权衡说明了机器学习中最重要的挑战之一。如何创建一个表现良好的模型,同时保持其泛化到新的、看不见的数据的能力? 我们的算法在此类数据上的性能由测试误差来量化衡量。测试误差可以进一步分解为偏差和方差。
偏差量化了模型在训练数据上的拟合质量。低偏差意味着模型在训练数据集上的错误率非常低。
方差量化了模型对训练数据的敏感性。换句话说,如果用另一个数据集替换现有训练数据集,训练错误率会改变多少?低方差意味着模型对训练数据不敏感并且可以很好地泛化。
验证集和交叉验证
交叉验证是一组技术,用于评估模型泛化和缓解过度拟合挑战。通常可以利用验证集方法,将可用数据分为两部分:
- 一个训练集,用于训练算法模型(通常是可用数据的 80-90%)
- 一个验证集,用于评估创建的算法(可用数据的 10-20%)
还有其他交叉验证方法,例如LOO(Leave One Out)或k折交叉验证,但它们不适合深度学习算法。
3.4 TFRecord
TFRecord是TensorFlow的自定义数据格式。尽管在技术上不一定需要使用TensorFlow训练模型,但这种数据格式非常有用。对于一些预先存在的TensorFlow API,需要使用TFRecord格式来训练模型。
Python处理Waymo开放数据集tfrecord数据
import io
import os
import tensorflow.compat.v1 as tf
from PIL import Image
from waymo_open_dataset import dataset_pb2 as open_dataset
from utils import parse_frame, int64_feature, int64_list_feature, bytes_feature \
bytes_list_feature, float_list_feature
def create_tf_example(filename, encoded_jpeg, annotations):
"""
convert to tensorflow object detection API format
args:
- filename [str]: name of the image
- encoded_jpeg [bytes-likes]: encoded image
- annotations [list]: bboxes and classes
returns:
- tf_example [tf.Example]
"""
encoded_jpg_io = io.BytesIO(encoded_jpeg)
image = Image.open(encoded_jpg_io)
width, height = image.size
mapping = {1: 'vehicle', 2: 'pedestrian', 4: 'cyclist'}
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
filename = filename.encode('utf8')
for ann in annotations:
xmin, ymin = ann.box.center_x - 0.5 * ann.box.length,
ann.box.center_y - 0.5 * ann.box.width
xmax, ymax = ann.box.center_x + 0.5 * ann.box.length,
ann.box.center_y + 0.5 * ann.box.width
xmins.append(xmin / width)
xmaxs.append(xmax / width)
ymins.append(ymin / height)
ymaxs.append(ymax / height)
classes.append(ann.type)
classes_text.append(mapping[ann.type].encode('utf8'))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': int64_feature(height),
'image/width': int64_feature(width),
'image/filename': bytes_feature(filename),
'image/source_id': bytes_feature(filename),
'image/encoded': bytes_feature(encoded_jpeg),
'image/format': bytes_feature(image_format),
'image/object/bbox/xmin': float_list_feature(xmins),
'image/object/bbox/xmax': float_list_feature(xmaxs),
'image/object/bbox/ymin': float_list_feature(ymins),
'image/object/bbox/ymax': float_list_feature(ymaxs),
'image/object/class/text': bytes_list_feature(classes_text),
'image/object/class/label': int64_list_feature(classes),
}))
return tf_example
def process_tfr(path):
"""
process a waymo tf record into a tf api tf record
"""
# create processed data dir
file_name = os.path.basename(path)
logger.info(f'Processing {path}')
writer = tf.python_io.TFRecordWriter(f'{dest}/{file_name}')
dataset = tf.data.TFRecordDataset(path, compression_type='')
for idx, data in enumerate(dataset):
frame = open_dataset.Frame()
frame.ParseFromString(bytearray(data.numpy()))
encoded_jpeg, annotations = parse_frame(frame)
filename = file_name.replace('.tfrecord', f'_{idx}.tfrecord')
tf_example = create_tf_example(filename, encoded_jpeg, annotations)
writer.write(tf_example.SerializeToString())
writer.close()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('-p', '--path', required=True, type=str,
help='Waymo Open dataset tf record')
args = parser.parse_args()
process_tfr(args.path)
4. 模型选择
4.1 模型选择
ML工程师通常会对创建新模型感到兴奋。但是,在深入ML工作流程的这一步之前,必须通过设置基线来设定切合实际的期望。
下限基线用于了解最低预期性能。如果指标低于此类基线,则应发出警告信号,并应检查是否训练管道出现问题。例如,对于分类问题,随机猜测基线是一个很好的下限。给定C类,算法准确度应高于1/C,也就是说至少得比随机猜测的准确性更高。
上限基线用于了解最高的预期性能。如果有人要求使用一种算法来对图像进行100%的正确分类,可以直接告诉他这无法做到。人类表现是一个很好的上限基线。对于分类问题,应该尝试手动对100幅图像进行分类,以了解算法可以达到的性能水平。
模型选择是ML工作流程的动态部分,它需要多次迭代。除非对该任务有一些先验知识,否则建议从简单的模型开始,之后再在复杂性上进行迭代。请记住,验证集在此阶段应保持不变!
4.2 误差分析
验证集指标是模型全局性能的一个很好的参考指标,但我们通常需要更好的理解。例如,像准确性这样的指标不会告诉我们某类对象是否总是被错误分类。由于这些原因,必须在对模型进行迭代之前进行深入的错误分析。
根据度量或损失值对预测进行排序始终是识别错误模式的有用方法。
5. 总结
机器学习工作流程如下:
-
构建问题:了解风险,定义相关指标。
-
理解数据:执行探索性数据分析,从数据集中提取模式。
-
迭代模型:创建验证集,设置基线,从简单到复杂的模型迭代。